编者按:
今年的 5 月 20~21 日,达能纽迪希亚和热心肠研究院联合搞了一场特别的会——邀请了 8 位重量级专家出镜发表线上演讲,作为为期 8 天的第六届纽迪希亚生命早期营养国际研讨会(首届云端高峰论坛)的组成部分。

今天我们特别整理并发布王军老师的演讲视频及图文实录,以飨读者。
王军:
中国科学院微生物研究所研究员
中国肠道大会联合发起人&执行主席
热心肠智库专家
中国科学院微生物研究所研究员,博士生导师。2017 年入选中组部“千人计划”青年项目。主要进行生物数据的深度挖掘和分析工作,工作中利用统计学和生物信息学结合的方法,研究肠道菌群在动物和人类生态、基因组进化和疾病中的作用。至今,在 Science,Nature,Nature Genetics 等国际一流科技刊物上发表 SCI 论文 23 篇,承担重大基金项目 2 项,申请专利 1 项。
以下是图文实录:

各位老师同学,大家下午好,非常高兴能在这样一个虚拟的平台跟大家交流我们自己在微生物组领域的一些见解。
大家可能听说了,我们国家现在正在进行新一轮基建。其中非常重要的几个发展点就是大数据、5G 以及人工智能等方向。关于微生物组的研究其实我们也正在利用这些新的发展点,包括数据的增长,包括人工智能的发展等等。
所以,今天在这里面给大家讲一下我们自己的一些粗浅的见解。
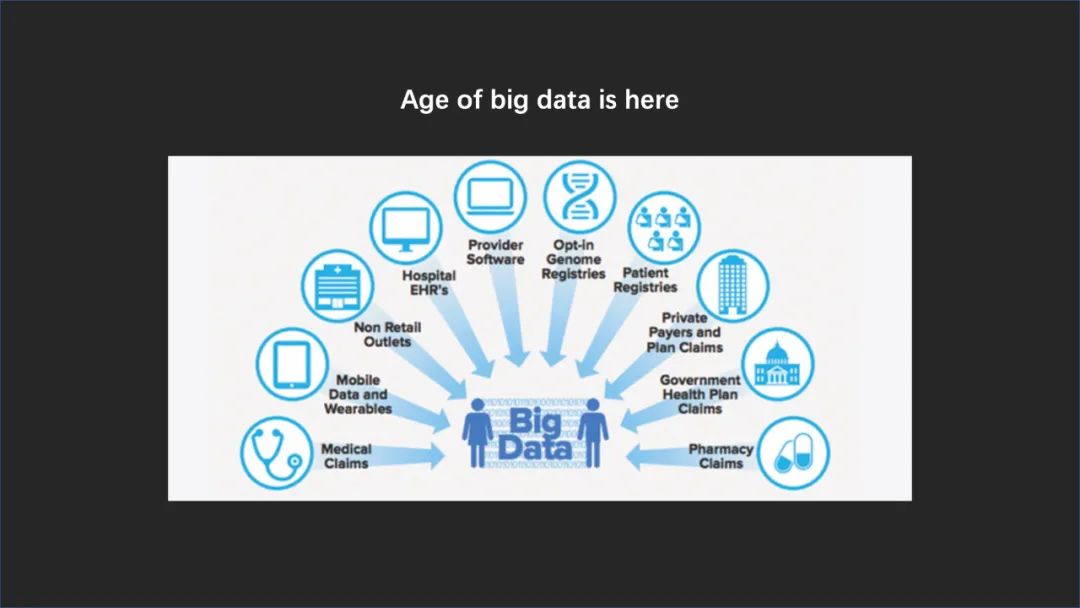
我们现在的生活已经被大数据所包围了。我们的医疗数据是大数据,我们的出行数据是大数据,我们的经济行为、购买行为都是大数据。
这些大数据不光是能够给很多我们自己的行为进行描述,同时也给很多的商家、很多的政府机构提供了一个非常宝贵的机会来进行一些新政策的指导,比如一些刺激消费政策的提出。
同时我们也知道,这种大数据的发展是会持续地发展的,所以我们真正的是在大数据时代的一个最蓬勃发展的时期,但是同时也是相对来讲比较初期的这样一个阶段。

大数据有这么几个特征,我们叫做 Big FOUR。
Big FOUR 的话,就是它的量很大,它的 Volume(大量)很大,它的 Velocity(高速)就是速度也会很快,数据传输可以实现百兆、千兆,甚至万兆每秒的这样一些传输速率。
Variety(多样)是说我们有什么样类型的数据,比如说我们看到的这些社交媒体大数据是我们自身交流信息,还有生活状态的一些内容,包括我们微信朋友圈,还有一些经济的数据,比如说我们花钱买什么。
我们自己以及很多做基础医学研究的人最关心的其实是人的健康数据,这些数据有多少,牵涉到我们什么样的方面,同时我们能用这些数据再去做什么。
最后一个就是 Veracity(真实性),就是我们能用这些数据,再去延伸做什么,就是它的这种多样性、它的这种可用性以及这些数据之中的一些价值。
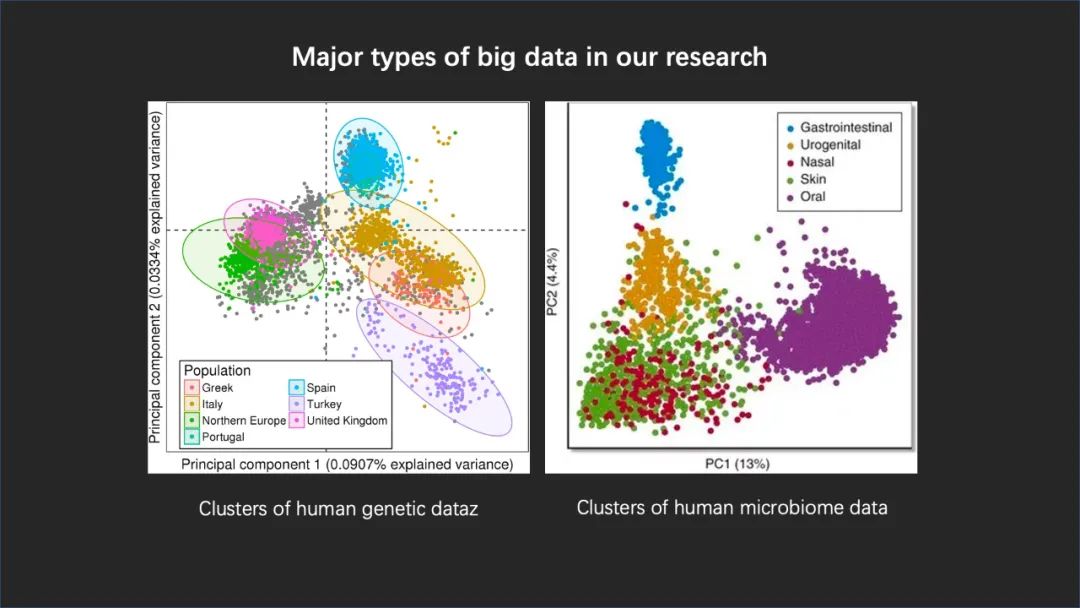
我们自己在做的主要的两大类数据:一个是人自身的基因组数据,包括这种基因变异的数据;另一个呢,在微生物所这样全国领先的微生物研究机构,所研究的微生物组学数据。
在过去的 20 年左右,我们首先对于自身的基因组有了初步并且快速发展的这样一个认识。我们从最早的几个人的基因组,慢慢地发展到几千人、几万人,甚至十几万人的基因组信息。
在左边这张图上,我们可以根据这些信息很明确的分出来各个地域、各个不同民族之间有明显的这种基因组上的区别,包括一些单碱基的变异和一些大规模的变异等等。通过这些数据,我们其实就可以反推出他们之间相互的这种亲缘关系,以及他们在历史上的变迁、 相互的通婚和交互等等。
而右边同样是高维度的数据,只不过这次我们看到的是宏基因组,也就是我们肠道或者其他地方微生物组的组成以及功能的数据。
比如说在这张图里面,我们发现肠道菌群是我们研究最多的一个菌群,但它其实并不是最有代表性的一个菌群,我们的皮肤、我们的呼吸道,甚至生殖道系统等等,它们的菌群是和消化道完全不一样的。虽然对于它们的研究相对来讲比较少,但是在健康领域,在对人的健康和疾病的影响方向,它们的重要性一点都不逊于肠道微生物组的贡献。

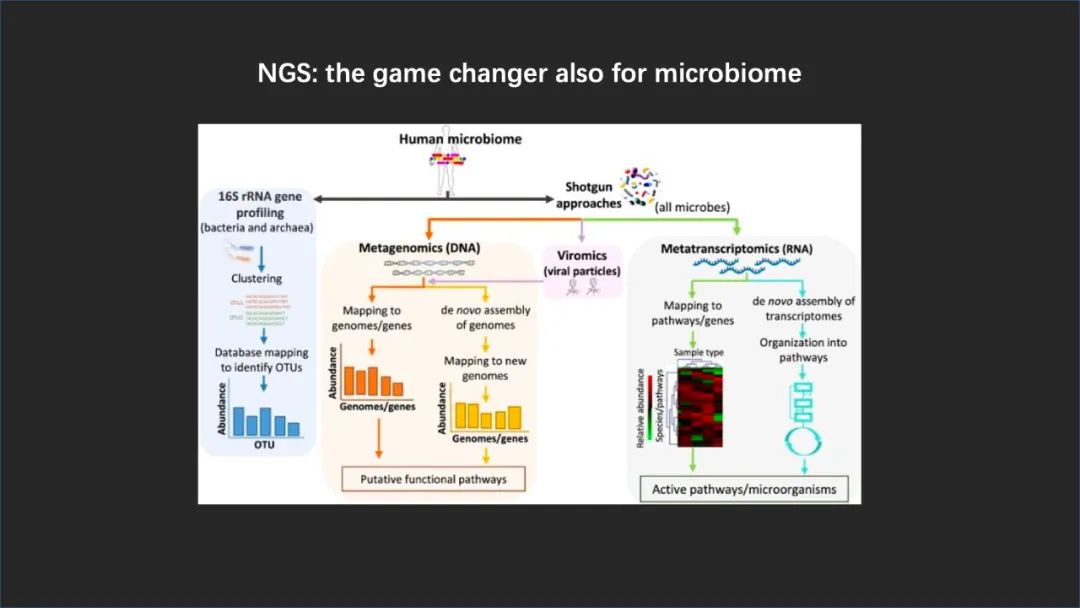
过去的 10 多年是我们能够获取这些数据的能力快速增长的 10 多年,因为我们有了一个 game changer,这就是在生物医学领域有着突破性变革的第二代测序技术,或叫下一代测序技术。
在 16S rRNA 作为宏基因组的主要 Marker 的基础之上,我们开始对于微生物组全新的、更全面的这种研究也是全靠第二代测序技术。
它的发展使我们能够获得与之前相比完全不是一个等级的 16S rRNA 的数据量。
之前我们可能用好几周,甚至好几个月的时间才能获得几十条、几百条的细菌的 16S rRNA 的数据。但是我们现在通过一次二代测序就可以获得几万条、几十万条,甚至更多的这种数据,我们可以一次获得很多生境里面主要的代表性细菌的这种分类学组成,就知道什么细菌在那个地方。
除了做 16S 这种传统的、比较保守的生物学 Marker 之外,我们还可以进行全部的宏基因组的 DNA,甚至 RNA 的分析,随之就产生了宏基因组和宏转录组这样的一些代表性研究。
在这个研究里面我们通过对 DNA 或者是 RNA 反转来的 cDNA 这种全部的测序,明确了很多微生物组在更精细的水平上的组成以及它们究竟发挥什么样的功能。
在中间还有一个非常小的模块叫做病毒组学,病毒组学也是随着二代测序技术的发展逐渐发展起来的这样一个学科。但是我们现在对它的这种投入以及对它的了解还是相对比较少的,主要还是一个方法学上的一些限制。

在生物信息学利用这些数据的历史上,可能最大的就是人类基因组学的这样里程碑式的一系列研究。
在本世纪初的时候,我们成功破解了人的基因组,随后我们从几个人的基因组,就慢慢发展到了几十个几百个,甚至几千个人的基因组。比如说有一个专门的项目叫做 1k genome project——1 千人基因组的研究。
后来,又有一些国家发展了国民基因组计划,比如说英国,比如说冰岛等等。这些国家相对来讲人口要比我们少很多,特别关注整个国民的基因组组成,所以他们提出了非常大的这种测序计划,包括 Genomics UK 这样测序超过 1 万人的基因组测序项目,以及现在仍然在进行的冰岛测序项目。
冰岛人口相对来讲是非常少的,然后通过这个项目他们可以实现整个国民 10%,甚至更多的这种基因组的研究,并且在这个项目里面也发现了非常多有意思的现象,大家有兴趣的可以去看专门的科普报道。

同样在宏基因组的研究方向,我们也有一系列这种地标性质或者是里程碑式的研究,最有代表性的就是著名的人类微生物组计划(Human Microbiome Project)。
世界上很多的实验室和科学家共同解析了人类微生物组的图谱,包括我们最常见的肠道微生物组,包括我们的呼吸道、生殖道,以及其它地方的微生物组等等。
这是我们第 1 次有概念,我们的肠道、皮肤以及其它地方有多少不同的细菌,然后这些细菌的动态变化是什么,它们可能编码的基因又能做什么,以及对于我们的健康有可能产生一些什么样的影响等等。
在那之后,他们又开展了第 2 期的微生物组计划,叫做 iHMP。样本量从原始的 300 多一直拓展了后面的将近 2000 人,然后每个人会有各种各样不同位置的微生物组数据,以及随着时间变化的数据。在这个里面,我们也初步看到了很多与疾病相关的一些微生物组的变化等等。

当然,除了这个项目之外,还有很多专门的针对不同疾病以及不同的人群所建设的微生物组的研究项目。
比如说欧盟和中国华大以及另外的几个单位一起参与的 MetaHIT 项目。它是专门针对不同国家 2 型糖尿病患者与正常人菌群的不同,有很多非常著名、非常有影响力的研究成果在这里面被发现出来,比如说 enterotype 肠型这个概念,以及 mGWAS(微生物组的全基因组关联)等等。
下面这个图是一个叫做 TwinsUK 的项目,在这里面所有的人都是双胞胎,有一些是同卵双胞胎,有一些是异卵双胞胎。这样的一个设置或者这样一个人群就提供了一个非常好的研究基因型对于微生物组以及其它性状影响的平台。
我们知道同卵双胞胎和异卵双胞胎的生活环境基本上是一致的,但是他们的基因型在异卵双胞胎里面是 50%左右,而同卵双胞胎的话,他们的相似性是 100%。这样的话,一些性状如果真的是和基因密切相关的,我们能在这两类双胞胎中看出明显的不同。
而且事实证明,在菌群方向,我们也确实看到了这两类的不同,从而确定了人类基因组对于微生物组明显的影响。

在 2016 年,我们的微生物组研究进入了大数据时代,真正的大人群时代。
在这一期的 Science 上, 包括我在博后时候的实验室以及荷兰的一个研究组各自发表了 1000 人以上的宏基因组数据,以及与各项生活习惯、用药、血常规,还有其它的一些全面的指标之间的关联性研究成果。
在这里面,我们首次利用几百个指标去对应几百个不同的细菌成分,这样的研究真的只能在几千人以上的这种数据里面才能实现。

同样是 2016 年,11 月份的时候 Nature Genetics 也是以封面文章的形式发表了三篇这样的研究。
在这里面,我们就初步探究了或者说初步建立了在人类基因组里面真正影响微生物组的突变位点以及变异的图谱,找到了非常多的和我们已知的一些疾病非常相关的一些位点。这样的话,我们就确定了微生物组在很多疾病中可能发挥的这种间接或者是直接的作用。

我们现在可以对于微生物组的这样一些变异,或者是人与人之间的不同做一些总结。我们知道一些主要的因素怎么样去影响微生物的不同,以及这些不同又反过来怎么影响人类健康。
比如说刚才提过的我们人和人之间的这种肠型很有可能就是不一样的,它像我们的血型一样可以分成不同的型。这种型表现成细菌组成的不同,但同时也表现成疾病发病频率的不同。
我们现在的研究基本上认为,这种肠型主要是我们的饮食决定的:长期饮食决定我们肠型。基因有一定的影响,但是比饮食要小一部分。反过来,我们现在也知道,由于饮食导致的微生物组的不同也会影响我们自身的这种健康。
比如,在 Cell 上发表的一系列的文章已经明确我们吃的很多饮食,我们吃的很多肉食性的这种食物会被我们的肠道微生物变成叫做三甲基亚胺以及氧化三甲基胺这样一些物质。
而这种转化能力的不同在很多人里面能够进一步的影响这些人心血管疾病发病的频率,因为氧化三甲基亚胺和三甲基亚胺是非常重要的调节心血管疾病发病率的化学物质,或者说代谢产物。
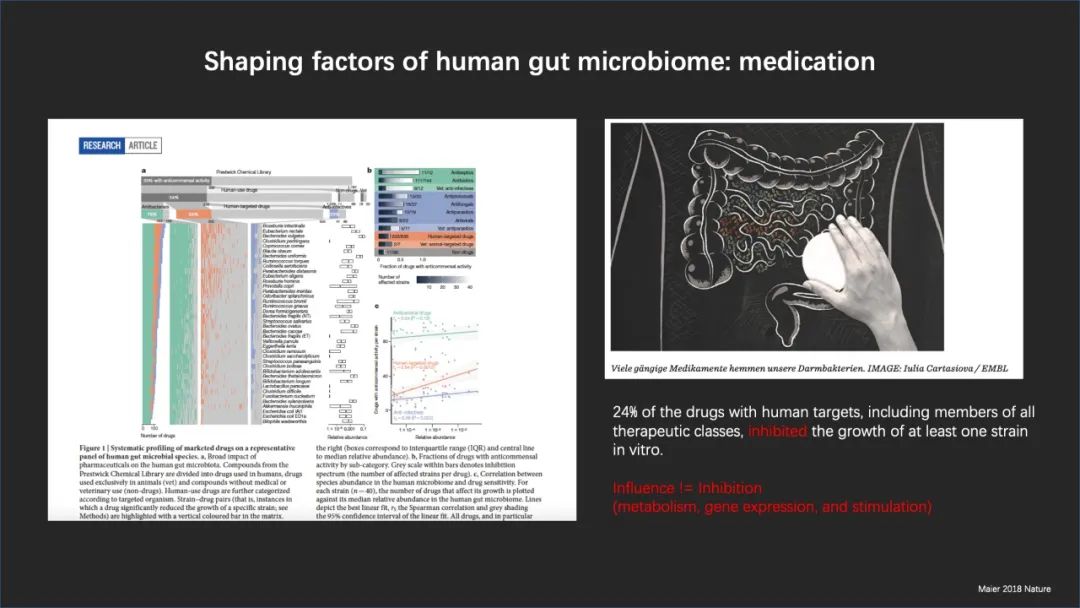
我们也知道,很多的用药能够影响我们微生物组的这种不同,即使这些药一开始的时候并不是作为抗生素来使用的。至少有 20%以上的已知常用药能够对于微生物产生一些抑制作用,可能会造成肠道的稳态失衡。

可能参会的同学和老师特别关心的一点就是婴幼儿的这种健康,还有与菌群之间的关系。这里我可以给大家推荐两个非常著名的研究体系,一个叫做 DIABIMMUNE,另外一个是下一张图的 TEDDY 这样一个系统。两个研究都是由美国 Broad Institute 带头实施的,在过去的很长一段时间里特别关注婴幼儿微生物组的发展以及与健康的关系。
比如说,他们发现抗生素的使用在一些儿童中导致了菌群的失调,多样性的降低,而这种多样性的降低和 1 型糖尿病的发病是有非常明确的关系的。所以在婴幼儿的发育和成长过程中,怎样去尽量避免,或者是减少抗生素的使用,怎样避免肠道菌群的失衡,以及避免这种自发性免疫性疾病的发生是我们之后要非常关注的一个话题。

还有刚才说的 TEDDY 项目,TEDDY 是一个更大的研究,所参与的婴幼儿更多。基于这个研究,我们基本上可以把婴幼儿的肠道菌群发育发展分成三个阶段:一个就是 3~14 个月的时候,这是一个初始的发展期;然后 15~30 个月的时候是一个转型期;最后在 31~46 个月的时候,他们才真正的实现稳定。
而在每个阶段所发生的人为的干预、干扰,或者是一些不精心不经意的干预、干扰,都可能对于婴儿的发展产生不可估量的影响。
婴幼儿的菌群比较简单,容易受到影响,但并不是说青少年之后,成年之后,他们就不受影响了。同样很多因素在影响菌群的这种组成和功能,所造成的菌群失调就有可能导致一些疾病的发生。
我们现在已经知道,菌群能够和基因的背景相互作用。
比如说同样的饮食,一些人吃了就迅速发胖,另外一些人怎么吃都不胖,那我们就要考虑这个人本身基因型的问题。是不是他的代谢的基础率会更高一些?第二个,他们是不是有更多代谢时候特别有效率、特别高效的菌群?这样的话,我们就能够去同时兼顾营养、人的基因和菌群这几个方向的互作对于人的健康最重要的影响。
并且我们对于婴幼儿的健康还开始往前推,就是对于孕期母亲的健康。我们也发现肠道菌群、阴道菌群等等虽然不会直接和婴幼儿发生接触,或者说在怀孕的时候不直接发生接触,但是肠道菌群的很多代谢产物以及在生产过程中阴道菌群与儿童这种接触等等一旦发生改变,我们就能够看到婴幼儿肠道菌群发展的不同以及在健康指标等方向的差异。
这也告诉我们,如果我们是想关注一个人的健康发育的话,其实就应在孕期甚至孕前就开始进行关注整个菌群的差异和干预以及不同的干扰因素;然后从产后一直到成年,甚至到老年,我们都需要以菌群作为其中的一个出发点去关注这个人的健康,去调理或者去影响一个人的健康。

我们怎样去做这样一些事情,怎么样把它整合成大数据,然后去研究呢?
我们就需要 BioBank ,需要这种生物的样本库,需要进行非常系列的长期追踪,包括刚才说的从孕期,甚至孕前开始追踪一系列的人群,然后不停地收取各种各样的样本。
通过不断积累数据,通过这些数据有针对性的分析,我们才能够发现越来越多需要去关注的因素,这需要非常大的一些投入,而且很多时候,也是比较耗时间的,但是这些事情真的是需要做。
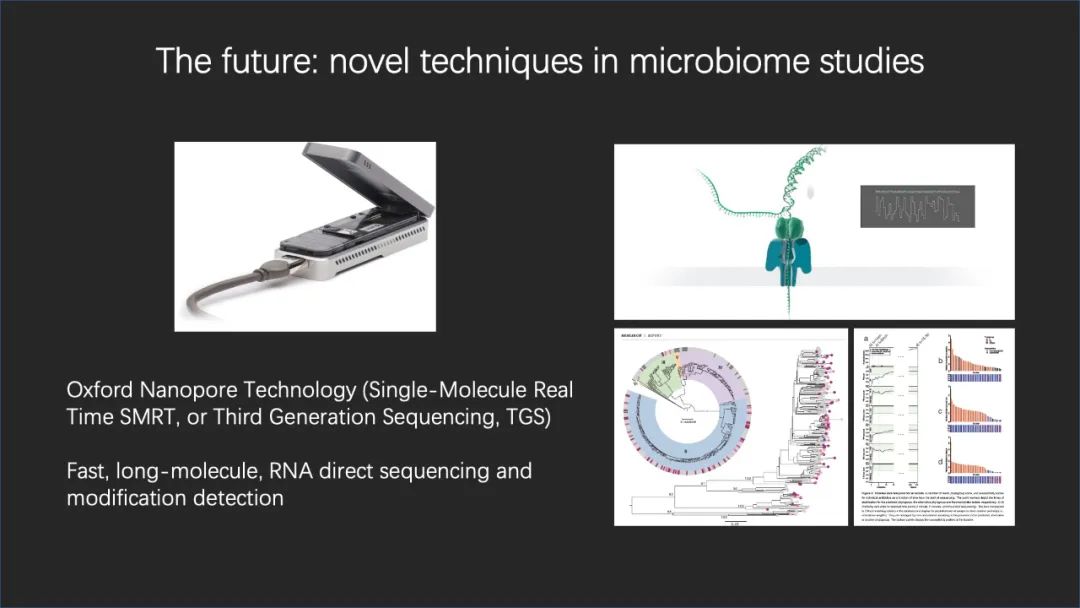
我们刚才说了,过去 10 年、20 年生物医学的进展特别得益于第二代测序技术,就是 NGS 技术的发展。现在我们非常有幸迎来了 TGS,就是第三代测序技术,也就是迎来了单分子实时荧光测序技术的发展和兴起。
其中一个代表就是英国牛津纳米孔公司所研发的 ONT 系统。这种检测平台可以实现 DNA 或者 RNA 分子更长的直接测序,还能够在一些 DNA 或者是 RNA 分子上看到它们的一些修饰的信息,所以我们能看到更多组学。
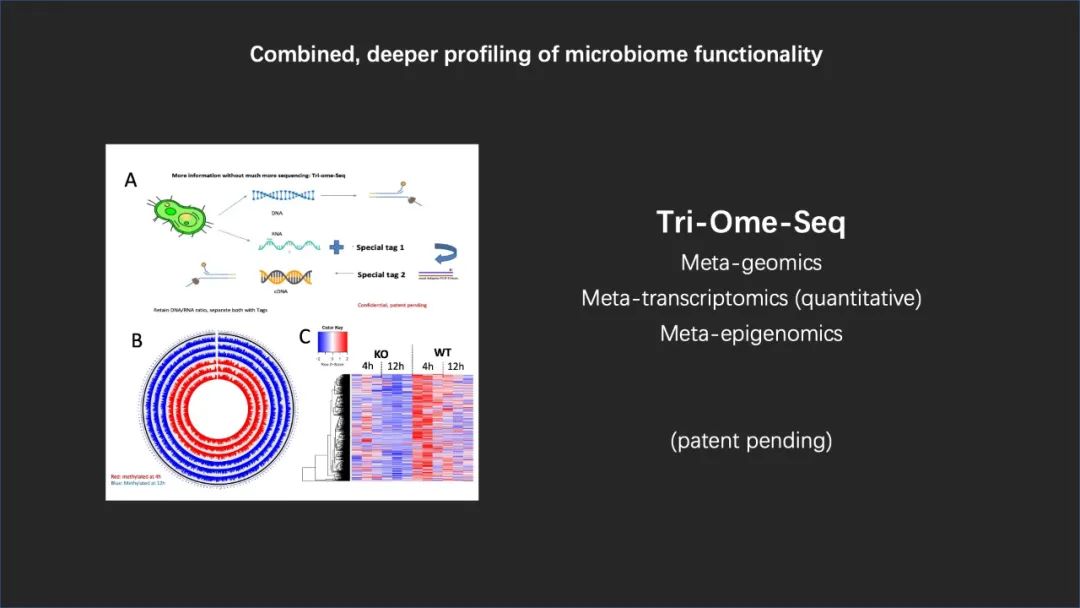
我们自己工作组在过去的时间里面发展了一个叫做 Tri-Ome-Seq 的测序技术,它可以实现宏基因组、宏转录组,以及宏甲基化组的同时检测。我们现在已经在很多的人群里面进行这种全面的大数据的积累和分析。

同时,我们利用这个技术已经开始解析人的病毒组,尤其是肠道病毒组。
我们在过去的一段时间里面,对于病毒组是相对比较忽略的,但是一些基础性的研究,一些前沿性研究已经表明,尤其是在婴幼儿里面,病毒组的发生发展与健康是息息相关的。
同时,在成人里面,我们也知道很多疾病的发生,不光有微生物组的变化,不光有微生物组的失调,他们的病毒组也发生了非常明显的变化。
我们工作组最近发表的文章就是利用宏基因组病毒组的这种提取富集技术,结合三代测序进行了全基因组的测序以及拼接工作。利用三代测序我们能够获得很多病毒的全基因组,而且是直接获得,不需要之前的特别复杂那种拼装。这样的话节省了很多的计算,也节省了很多时间,有助于我们进行非常多的且深入的病毒组学研究。

最后,除了“大数据”这样一个比较炫的名词,大家很有可能也每天都被“人工智能”这样一个关键词所轰炸。
真正的人工智能现在发展前景非常广阔。但是我们所谓的这种比较宽泛的、能够自我思考的这种人工智能,就是在电影 Terminator 里面所描述的那种,现在还是非常难实现的,甚至有一些专家认为是基本上不可能实现的。
现在人工智能真正应用的领域都比较窄,是用来解决特殊问题的。所以有的人也非常有意思地称他们是“人工智障”。也就是说,我想要一个人工智能的算法,或者一个人工智能程序去做一件事情,它就做不了其它。对于人工智能这些算法,我们很多时候需要针对一个问题进行一次编程,针对另外一个问题这一套算法就完全失效了。
比如右边我去训练一个算法去判断一个动物是狗,还是猫。你可以让电脑训练非常好的算法,能够把狗和猫分得特别清楚、特别快,但是这样一个程序不能去做其它的,比如炒菜或者买菜这样的一些工作,所以这就是现在这种比较狭义的人工智能的一些限制。
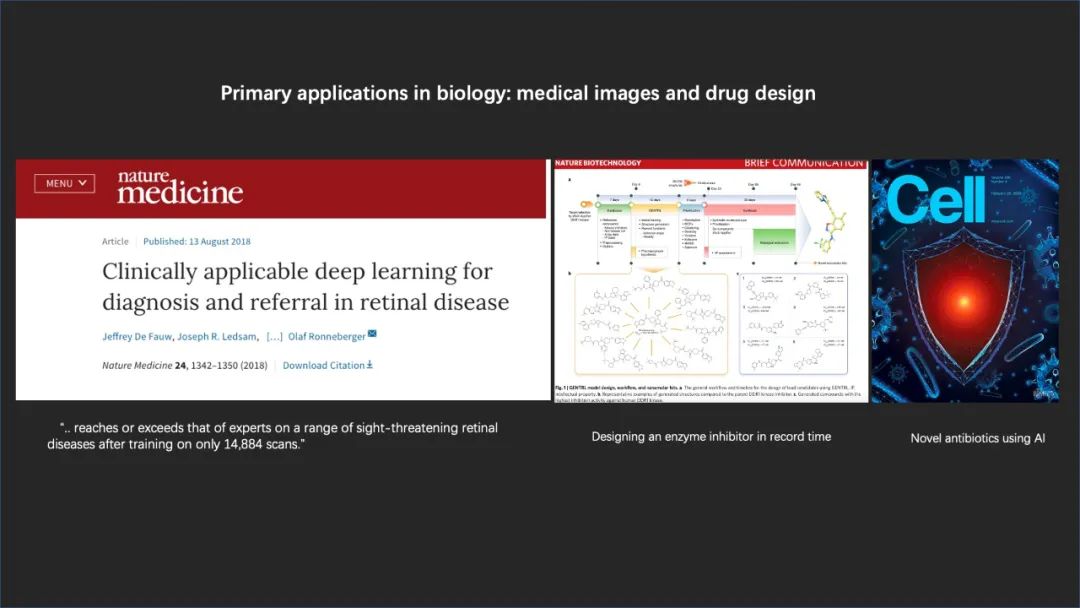
有限制并不是说做不好或者是没有用,尤其是过去两年之内,我们看到了人工智能在很多领域的快速发展及应用。在医学上,我们现在已经用人工智能去非常快、非常准确地分析很多医学影像数据,或者进行一些新药的研发等。
比如说最近在 Cell 上的一篇论文,他们用人工智能办法非常快地挖掘出了一个全新的抗生素,用了可能就十几天的时间就完成了过去普通制药行业几年、几十年才能完成的一件事情。所以,这些新的算法的应用真的在改变我们基础医学还有生命科学领域的面貌。

并且这种机器学习或者说这种深度学习已经在营养学方向被应用,这体现在以色列 Iran Segal 实验室两篇代表性的文章。
他们的主要思想或者他们主要的这种技术手段,就是我收集很多人肠道宏基因组的数据,收集他们一些生活的数据,收集他们饮食数据,然后先用这些大规模的组学数据去训练一个模型,最终实现对于同样一个人我可以判断:他吃不同食物所造成的这种餐后血糖的升高,以及不同人对于同样的食物所拥有的血糖反应。
这样,对于一些特殊人群,比如说 2 型糖尿病或者糖尿病前期人群的血糖控制是非常有意义的。
并且我们相信这种方法也是具有一定的通用性的,只不过我们对于任何的一个研究,或者对于任何的一个指标的预测都需要积累大量的数据才能真正的实现,我们自己的研究组也在涉足这个领域。
我今天的报告就到这里,非常感谢大家的聆听!